Machine Learning Fundamentals A Beginner's Complete Guide
Aug 1, 2025 • —

Machine Learning Fundamentals: A Beginner’s Complete Guide
tl;dr: A Beginner Complete Guide.
Machine Learning Fundamentals: A Beginner’s Complete Guide
Machine learning has become one of the most transformative technologies of our time, powering everything from recommendation systems to autonomous vehicles. If you’re new to this field, understanding the fundamentals is crucial for building a solid foundation. This comprehensive guide will walk you through the essential concepts, processes, and terminology you need to know.
What is Machine Learning?
Machine learning is a subset of artificial intelligence (AI) that enables computers to learn and make decisions from data without being explicitly programmed for every specific task. Instead of following pre-written instructions, ML systems identify patterns in data and use these patterns to make predictions or decisions about new, unseen data.
Think of it like teaching a child to recognize animals. Instead of describing every possible feature of a cat, you show them hundreds of cat pictures. Eventually, they learn to identify cats on their own by recognizing common patterns and features.
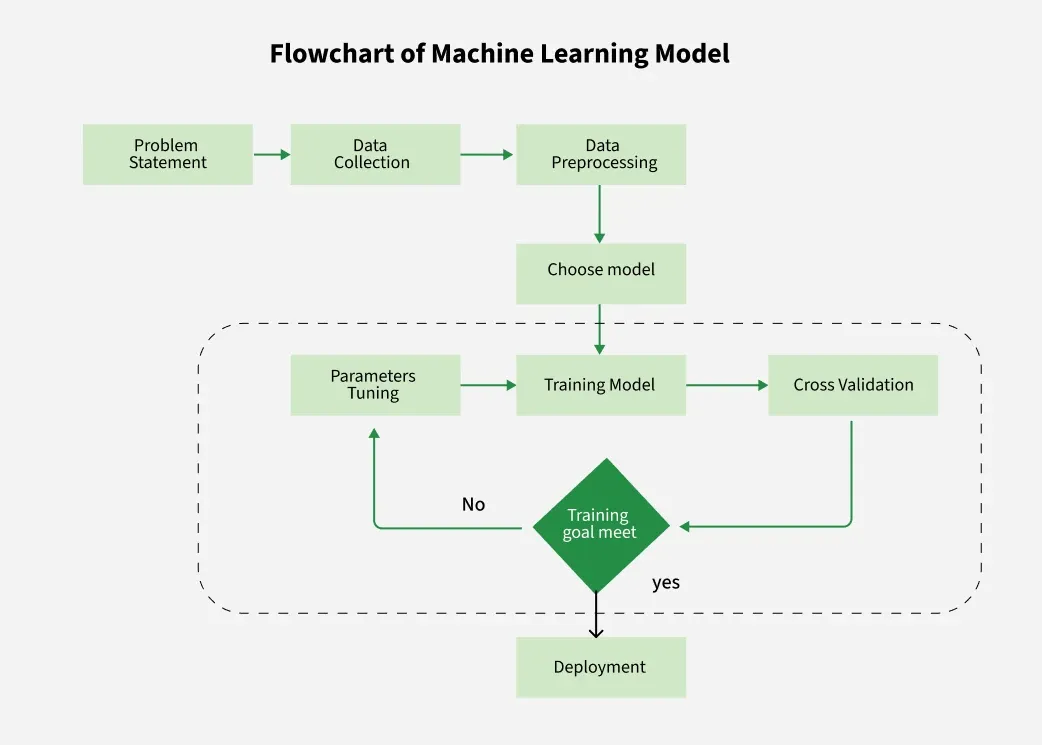
The Machine Learning Process
Building a machine learning model involves several key stages that work together to create an intelligent system:
1. Data Collection and Preparation
The machine learning process starts with collecting and processing training data. There’s a famous saying in the ML community: “garbage in, garbage out.” This means that an ML model is only as good as the data used to train it. Data preparation and processing might seem routine, but it’s arguably the most critical stage that can make or break your model’s performance.

Types of Data
Labeled vs. Unlabeled Data:
- Labeled data: Each example comes with a correct answer or target variable. For instance, in an image classification task, labeled data would consist of images along with their corresponding class labels (cat, dog, car).
- Unlabeled data: Examples without any associated labels or target variables. This might be a collection of images without any labels or annotations.
Structured vs. Unstructured Data:
-
Structured data: Organized in a predefined format, typically in tables or databases with rows and columns. This includes:
-
Tabular data: Spreadsheets, databases, or CSV files with rows representing instances and columns representing features.
-
Time-series data: Sequences of values measured over time, such as stock prices, sensor readings, or weather data.
-
Unstructured data: Lacks a predefined structure, requiring advanced techniques to extract meaningful patterns:
-
Text data: Documents, articles, social media posts, and other textual content.
-
Image data: Digital images, photographs, and video frames.
-
Audio data: Sound recordings, music, and speech.
-
Video data: Moving images with temporal sequences.
2. Algorithm Selection
Once your data is prepared, you need to choose an appropriate machine learning algorithm. The choice depends on several factors:

- Problem type: Classification, regression, clustering, or other tasks.
- Data size: Some algorithms work better with large datasets, others with smaller ones.
- Interpretability needs: Some algorithms provide clear explanations, others are “black boxes.”
- Performance requirements: Speed vs. accuracy trade-offs.
3. Model Training
Training is where the magic happens. The algorithm analyzes your data to learn patterns and relationships. This process varies depending on the learning approach.
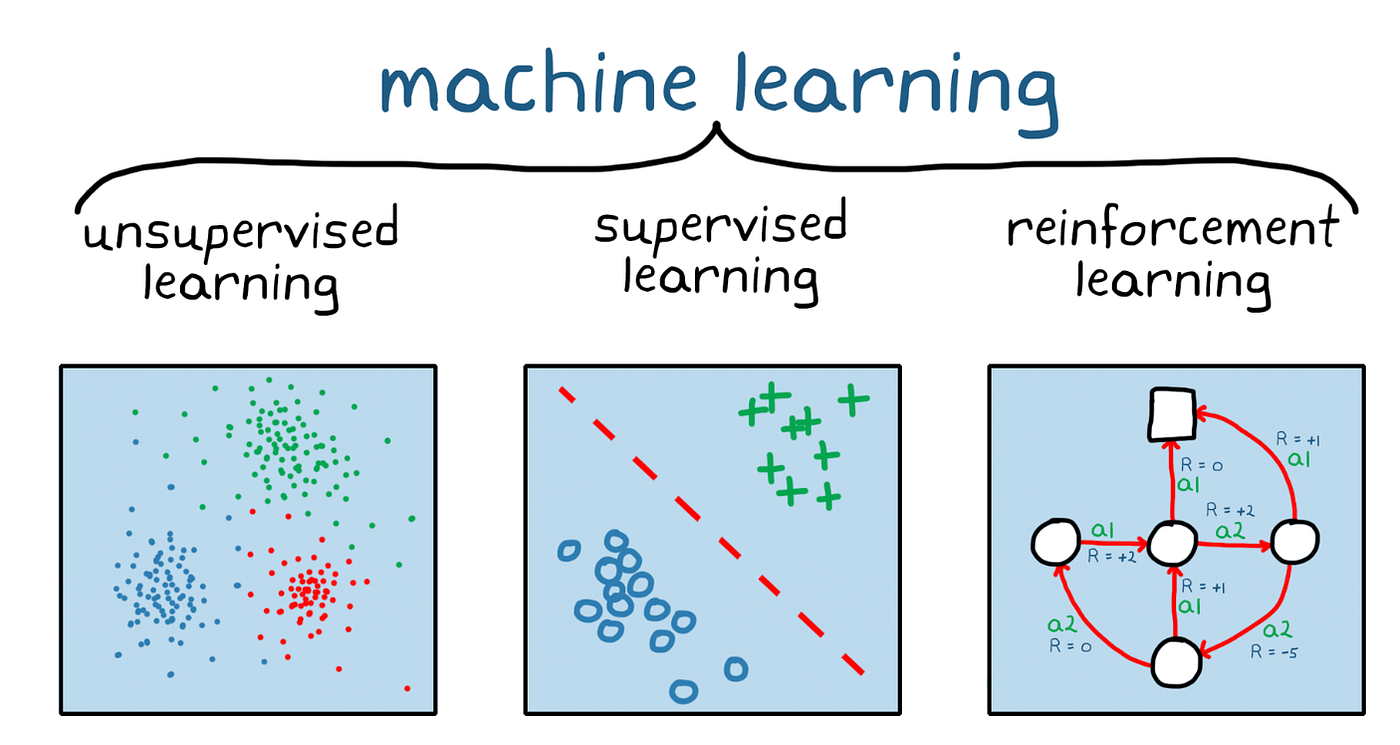
Types of Machine Learning
Supervised Learning
In supervised learning, algorithms are trained on labeled data. The goal is to learn a mapping function that can predict the output for new, unseen input data.
[Image comparing supervised vs unsupervised vs reinforcement learning]
Common supervised learning tasks:
- Classification: Predicting categories (spam vs. not spam, disease vs. healthy).
- Regression: Predicting continuous values (house prices, temperature).
Popular algorithms:
- Linear Regression
- Decision Trees
- Random Forest
- Support Vector Machines
- Neural Networks
Unsupervised Learning
Unsupervised learning algorithms learn from unlabeled data. The goal is to discover inherent patterns, structures, or relationships within the input data without knowing the “correct” answers.
Common unsupervised learning tasks:
- Clustering: Grouping similar data points together.
- Dimensionality reduction: Simplifying data while preserving important information.
- Anomaly detection: Identifying unusual patterns or outliers.
Popular algorithms:
- K-Means Clustering
- Hierarchical Clustering
- Principal Component Analysis (PCA)
- Association Rules
Reinforcement Learning
In reinforcement learning, the machine learns through trial and error, receiving feedback in the form of rewards or penalties for its actions. The goal is to learn the best actions to take in different situations to maximize cumulative rewards.
Key concepts:
- Agent: The learning entity.
- Environment: The world the agent operates in.
- Actions: What the agent can do.
- Rewards: Feedback from the environment.
- Policy: The agent’s strategy for choosing actions.
Applications:
- Game playing (chess, Go).
- Robotics.
- Autonomous vehicles.
- Resource allocation.
Model Evaluation and Validation
After training, you need to evaluate how well your model performs. This involves:
Performance Metrics
Different metrics suit different types of problems.
For Classification:
- Accuracy: Percentage of correct predictions.
- Precision: Of positive predictions, how many were correct?
- Recall: Of actual positive cases, how many were identified?
- F1-Score: Harmonic mean of precision and recall.
For Regression:
- Mean Squared Error (MSE): Average of squared differences.
- Root Mean Squared Error (RMSE): Square root of MSE.
- Mean Absolute Error (MAE): Average of absolute differences.
Cross-Validation
To ensure your model generalizes well to new data, you should use techniques like:
- Train-Test Split: Divide data into training and testing sets.
- K-Fold Cross-Validation: Split data into k parts, train on k-1, test on 1, repeat.
- Hold-Out Validation: Keep a separate validation set for final evaluation.
Inferencing: Putting Models to Work
After training and validation, it’s time to use your model to make predictions or decisions. This process is called inferencing.

Types of Inferencing
- Batch Inferencing: Processes large amounts of data all at once. Ideal for tasks where accuracy is more important than speed (e.g., monthly customer segmentation).
- Real-Time Inferencing: Makes decisions quickly as new information arrives. Crucial for immediate responses (e.g., chatbots, self-driving cars, fraud detection).
Common Challenges and Solutions
Overfitting and Underfitting
- Overfitting: Model memorizes training data but fails on new data. Solution: Use regularization, cross-validation, or simpler models.
- Underfitting: Model is too simple to capture underlying patterns. Solution: Use more complex models, add features, or train longer.
[Image illustrating underfitting, balanced fit, and overfitting]
Data Quality Issues
- Missing data: Use imputation techniques or algorithms that handle missing values.
- Outliers: Identify and handle extreme values appropriately.
- Bias: Ensure your data represents the problem you’re solving.
Scalability
- Large datasets: Use distributed computing, cloud platforms, or streaming algorithms.
- Real-time requirements: Optimize models for speed, use edge computing.
Getting Started: Your First Steps
- Learn the basics: Understand statistics, probability, and programming (Python or R).
- Practice with datasets: Start with clean, well-documented datasets.
- Use tools and libraries: Leverage scikit-learn, TensorFlow, or PyTorch.
- Join communities: Participate in Kaggle competitions, forums, and meetups.
- Work on projects: Apply your knowledge to real-world problems.
Key Takeaways
Machine learning is a powerful tool that can solve complex problems across various domains. Success depends on:
- Quality data: Clean, relevant, and representative datasets.
- Appropriate algorithms: Choosing the right approach for your problem.
- Proper evaluation: Using robust validation techniques.
- Continuous learning: The field evolves rapidly, so stay updated.